
Large Language Models (LLMs), such as OpenAI's ChatGPT and GPT-4, have made substantial advancements in artificial intelligence across various domains. However, these models often exhibit poor performance in applications that require domain-specific knowledge. To address this issue, we present PMC-LLaMA, an open-source language model that is fine-tuned on 4.8 million biomedical academic papers. Preliminary evaluations on three biomedical QA datasets, including PubMedQA, MedMCQA, and USMLE, demonstrate that PMC-LLaMA offers superior performance compared to the foundational LLaMA.
PMC-LLaMA Training Pipeline
PMC-LLaMA is trained by fine-tuning the LLaMA-7B model on 4.8 million biomedical academic papers sourced from the S2ORC dataset, which contains 81.1 million English-language academic papers. The fine-tuning process involves using an autoregressive generation objective and training the model for 5 epochs with 8 A100 GPUs in around 7 days. The resulting model, PMC-LLaMA, is then evaluated on three biomedical QA datasets.
Evaluation on Biomedical QA Datasets
The model is evaluated under three scenarios: full fine-tuning, parameter-efficient fine-tuning (PEFT), and data-efficient fine-tuning. In full fine-tuning, PMC-LLaMA is fine-tuned on the combination of the training set from PubMedQA and MedMCQA. For PEFT, the widely used method LoRA is employed. Lastly, data-efficient fine-tuning is conducted on the USMLE dataset.
Results and Performance
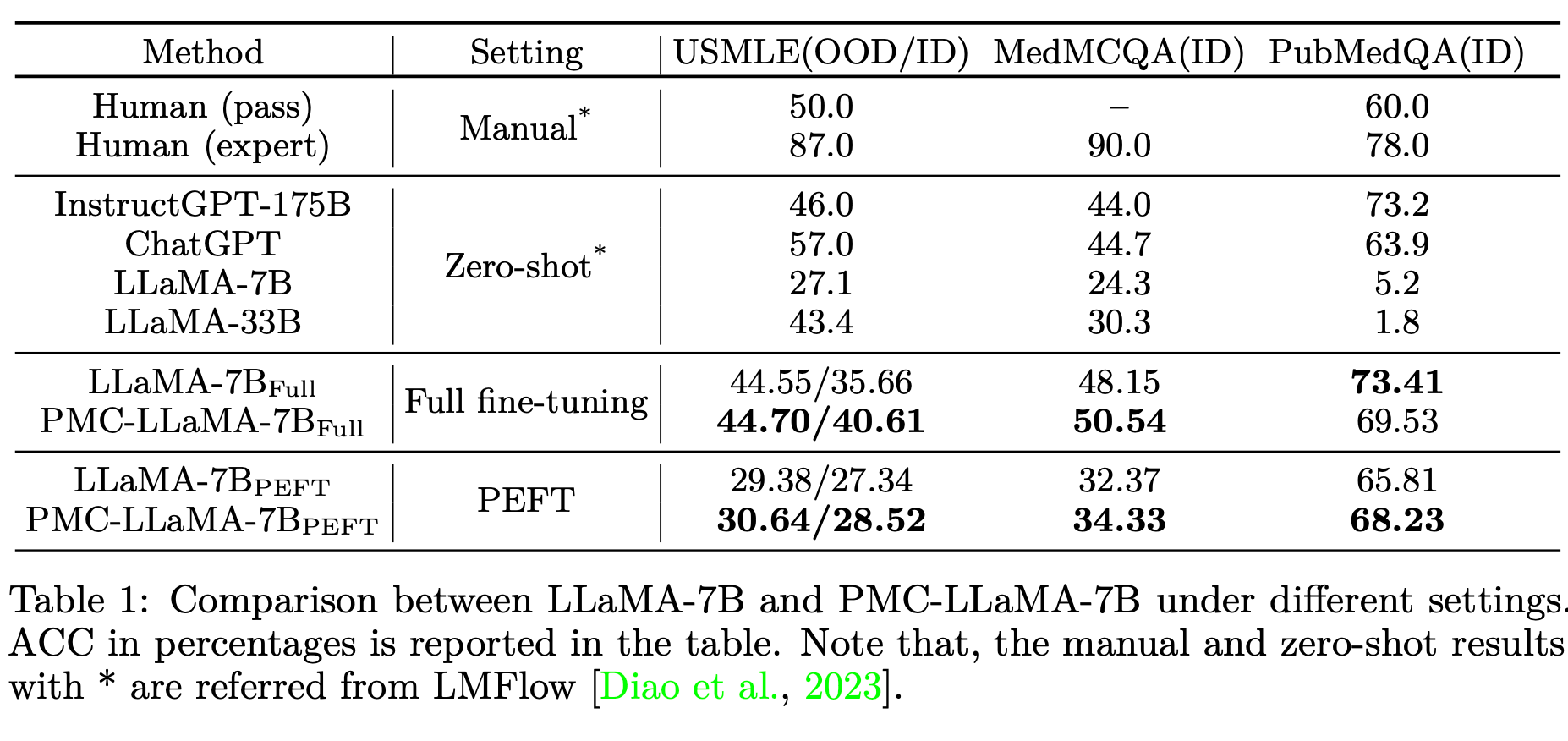
PMC-LLaMA demonstrates faster convergence and better performance than the original LLaMA across various medical QA benchmarks. For full fine-tuning, PMC-LLaMA outperforms LLaMA on two out of the three test sets. In parameter-efficient fine-tuning, PMC-LLaMA shows improved performance over LLaMA on in-domain datasets. In data-efficient fine-tuning, PMC-LLaMA achieves better results on the USMLE dataset compared to LLaMA.
Discussion
These results demonstrate that state-of-the-art language models can achieve respectable performance on medical question-answering tasks, especially when fine-tuned on domain-specific data. However, they still lag behind expert human performance, highlighting the need for further research and model improvements.
The differences in performance between zero-shot, fully fine-tuned, and PEFT models emphasize the importance of task-specific fine-tuning for enhancing AI models' abilities in specialized domains like medicine. Additionally, the variance in performance across different models and benchmarks underscores the need for more comprehensive evaluations of AI models in the medical domain.
While current language models show promise in the medical field, further advancements are necessary to reach the level of expertise and reliability that medical professionals and patients require. This includes developing models with a more profound understanding of medical concepts, improving reasoning abilities, and ensuring that AI-driven solutions are developed responsibly and ethically.
Comparing PMC-LLaMA Performance to ChatGPT
While evaluating the performance of PMC-LLaMA, it's essential to draw comparisons with other leading language models, such as OpenAI's ChatGPT. Although the two models demonstrate impressive capabilities in their respective domains, they differ in some key aspects.
Domain-Specific Knowledge
PMC-LLaMA has been fine-tuned on a vast corpus of 4.8 million biomedical academic papers, providing it with a substantial knowledge base in the medical field. As a result, the model exhibits superior performance on various medical QA datasets, including PubMedQA, MedMCQA, and USMLE. In comparison, ChatGPT, shows respectable performance compared to the fine-tuned models, while capable of handling daily dialogues and general question-answering tasks, may not perform as well in specialized areas like medical applications due to a lack of domain-specific knowledge.
Adaptability
PMC-LaMA's performance on medical QA benchmarks, following various fine-tuning scenarios, highlights its adaptability in the medical domain. The model excels in full fine-tuning, parameter-efficient fine-tuning, and data-efficient fine-tuning scenarios, demonstrating its potential for specialization in healthcare sub-tasks like medical dialogues or consultations. On the other hand, ChatGPT's performance in domain-specific applications remains unclear due to the lack of available information on its training details and model architectures.
Transparency
One of the significant advantages of PMC-LLaMA is its open-source nature, which allows researchers and developers to access and build upon its resources. The model's codes, along with an online demo, are publicly available for further experimentation and improvement. In contrast, ChatGPT and its variants have limited transparency, as their training details and model architectures remain undisclosed. This makes it difficult to ascertain their performance in specific domains or to determine if the evaluation data has been exploited during training.
Fine-tuned LLaMA Models vs Zero-shot GPT Models: Predictability and Comfort Level
When comparing fine-tuned LLaMA models with zero-shot GPT models (InstructGPT and ChatGPT) in the medical domain, an important factor to consider is the predictability and reliability of the results. Fine-tuned LLaMA models offer a certain level of comfort and predictability as they have been specifically trained on medical data, which allows them to perform better in specialized tasks and provide more reliable results.
On the other hand, the performance of zero-shot GPT models, such as InstructGPT and ChatGPT, may be less predictable due to the lack of information about the specific medical data they have been trained on. While these models have demonstrated impressive performance in general question-answering tasks, their ability to provide accurate and reliable results in specialized domains like medicine might be uncertain.
This unpredictability in zero-shot GPT models may lead to concerns for medical professionals who need accurate and reliable information to make informed decisions for patient care. In contrast, fine-tuned LLaMA models offer a higher degree of confidence in their results, as they have been specifically trained on medical data to enhance their performance in the medical domain.
Open Source Models and Data Privacy: GPT vs PMC-LLaMA Models
An important aspect to consider when deploying AI models in the medical field is data privacy and compliance with laws and regulations, such as the Health Insurance Portability and Accountability Act (HIPAA). GPT models, like InstructGPT and ChatGPT, are not open source and cannot be self-hosted. This limitation may raise concerns about sharing sensitive patient information with these models, as the data privacy and security risks associated with using external services could violate laws, treaties, and best practices for handling patient data.
In contrast, open-source models like LLaMA can be self-hosted, which provides an opportunity for healthcare organizations to implement stricter data privacy and security measures. By hosting these models locally or on private servers, healthcare providers can have better control over the data being processed, ensuring that sensitive patient information remains secure and in compliance with relevant laws and regulations.
Moreover, using open-source models in the medical domain allows organizations to customize and modify the models to better suit their specific needs, ensuring that the AI technology is tailored to the unique requirements of the medical field. This adaptability may lead to more accurate and reliable results, as well as more seamless integration with existing healthcare systems.
The Need For Follow-up Testing: Fine-tuned GPT Models vs Fine-tuned PMC-LLaMA Models
As a follow-up test, researchers should consider comparing fine-tuned GPT models with fine-tuned LLaMA models. This comparison will help determine if fine-tuning GPT models on medical data can result in similar or superior performance compared to the fine-tuned LLaMA models. Fine-tuning GPT models on medical data could potentially improve their predictability and reliability in specialized tasks, making them more suitable for use in the medical field.
By conducting this follow-up test, researchers can gain a better understanding of the capabilities and limitations of both GPT and LLaMA architectures when fine-tuned for the medical domain. This knowledge can then be used to further refine and develop AI models to better serve the needs of medical professionals and patients. Ultimately, such advancements in AI technology have the potential to revolutionize the medical field by providing more accurate and reliable assistance in decision-making processes and enhancing patient care.
PMC-LLaMA & ChatGPT: Implications For Medicine & Healthcare
The performance of language models on medical QA benchmarks has several implications for the medical field, professionals, and patients. The improvements in these models' capabilities can significantly impact medical practice, education, research, and patient care.
Implications for the Medical Field
- Improved decision support systems: As language models demonstrate higher performance in understanding and answering medical questions, they can be integrated into decision support systems to aid medical professionals in diagnostics, treatment planning, and patient management. These systems can provide more accurate and up-to-date information, reducing the risk of errors and improving patient outcomes.
- Enhanced medical research: Language models can be utilized in processing vast amounts of medical literature and data, enabling researchers to identify relevant studies, discover new patterns, and generate novel hypotheses more efficiently. This can accelerate the pace of medical research and contribute to the development of new treatments and therapies.
- Medical education and training: Advanced language models can be employed as learning tools in medical education, providing students and trainees with instant feedback, explanations, and supplementary resources. This can help them to develop a deeper understanding of medical concepts and improve their clinical decision-making skills.
Implications for Medical Professionals
- Time-saving and efficiency: By integrating AI-powered language models into their workflows, medical professionals can quickly access relevant information and insights, saving time on searching and reviewing the literature. This allows them to focus on patient care and make better-informed decisions, ultimately increasing their overall efficiency.
- Continuing education: Language models can support medical professionals in staying up-to-date with the latest advancements in their field, helping them maintain their expertise and expand their knowledge base. This, in turn, ensures that patients receive the best possible care based on current evidence and guidelines.
Implications for Patients
- Improved patient outcomes: As medical professionals receive more accurate and timely information from AI-powered language models, they can make better-informed decisions about diagnostics, treatments, and management plans. This can lead to improved patient outcomes, with a reduced risk of complications and errors.
- Patient education and engagement: Language models can be used to develop patient-facing applications that provide personalized, easy-to-understand explanations of medical conditions and treatment options. This can help patients become more informed about their health and more engaged in their care, ultimately leading to better adherence to treatment plans and improved health outcomes.
Takeaway
The development of domain-specific language models like PMC-LLaMA has demonstrated significant progress in enhancing the capabilities of AI in the medical field. By fine-tuning a vast corpus of biomedical academic papers, PMC-LLaMA has shown superior performance compared to foundational models like LLaMA across various medical QA benchmarks. Comparisons with models like ChatGPT underline the importance of domain-specific knowledge, adaptability, and transparency in ensuring accurate and reliable results in specialized fields.
The success of PMC-LLaMA has wide-ranging implications for medicine, healthcare professionals, and patients, including improved decision support systems, accelerated medical research, enhanced medical education, and better patient outcomes. Nevertheless, further research and model improvements are necessary to achieve expert human performance and ensure AI-driven solutions are developed responsibly and ethically. As AI technology continues to evolve, it has the potential to revolutionize the medical field, providing valuable support to medical professionals and patients alike.