

Recent advances in large language models (LLMs) like GPT-3, Jurassic-1, and Llama have unlocked new possibilities in natural language generation. One of the most promising of these is Meta's recent Llama-2.
What is LLama-2 LLM
On July 18th 2023 Meta introduced LLama-2, the successor to it's previous and successful Llama LLM.
 Sunil Ramlochan - Enterprise AI Specialist
Sunil Ramlochan - Enterprise AI Specialist


Meta's Llama-2 is a second-generation open-source large language model (LLM) developed by Meta and Microsoft. It is designed to enable developers and organizations to build generative AI-powered tools and experiences. Llama-2 is free for research and commercial use.
It can be used to build chatbots like ChatGPT or Google Bard. Meta has also released two versions of Code Llama, one geared toward producing Python code and another optimized for turning natural language into SQL queries.
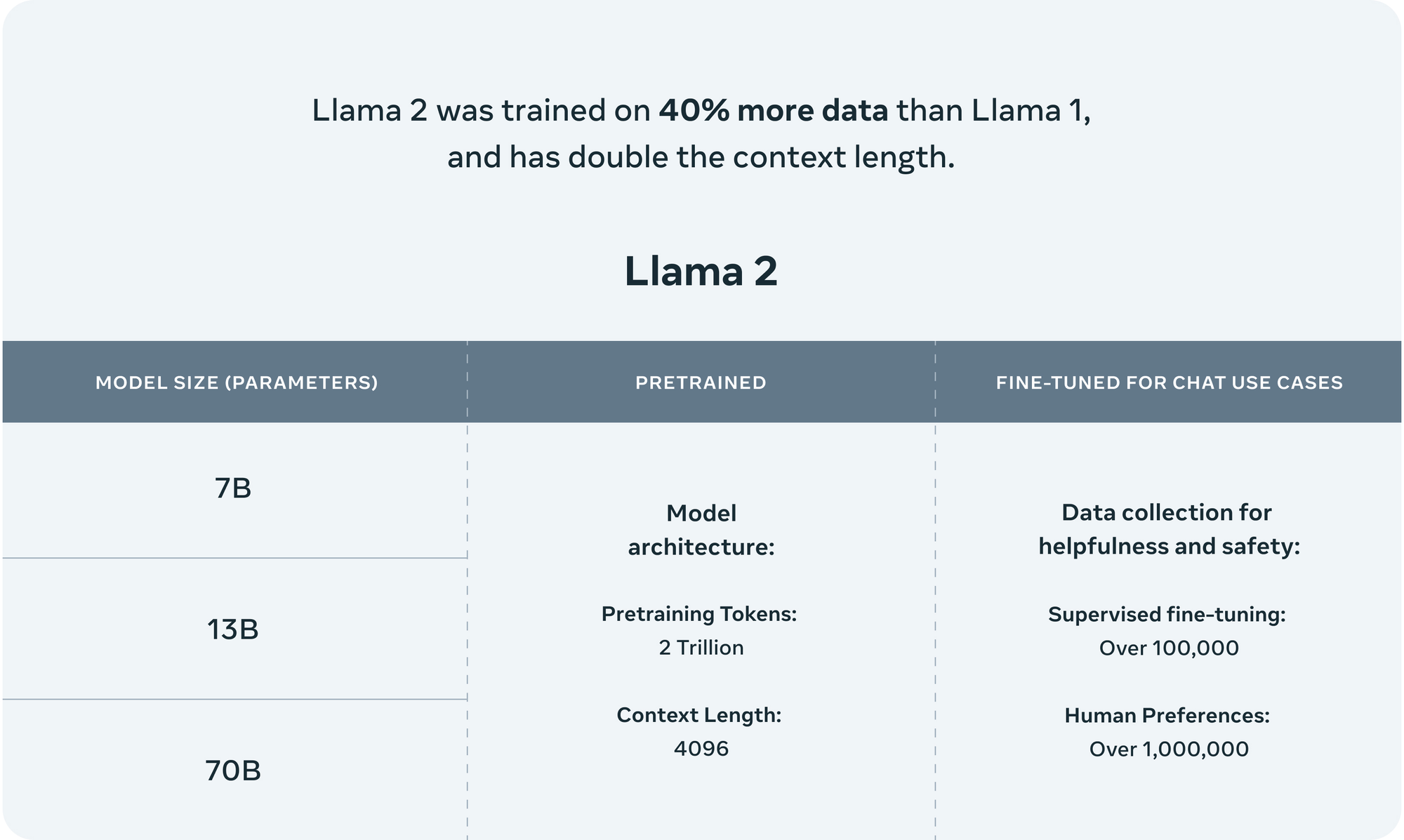
Llama Upgrade: Scaling Up with More Data
Llama 2 builds on Meta's previous Llama release, using 40% more training data and doubling context length. This additional data led to across-the-board performance gains.
The model architecture remains similar to Llama 1. But Meta's ability to leverage significantly more public data makes Llama 2 more capable.
Strong Performance Across Diverse Tests
Though just released, Llama 2 is already posting impressive numbers:
- The 34B Llama 2 tops similarly sized models like Vicuna-33B and Falcon-40B over 75% of the time in head-to-head matchups.
- Llama 2 scored 71.2% on Codex HumanEval for assessing Python coding skills - very high for an LLM.
- Building Llama 2 cost Meta an estimated $20 million - feasible for a company of its scale.
- Within 7 hours of launch, Meta's Llama 2-based chatbot gained 10 million users, showing strong demand.
- AI experts say Llama 2 could pose a real threat to closed models like GPT-4.
Llama 2 Outperforms Other Leading Open-Source LLMs
Llama 2 shows strong improvements over prior LLMs across diverse NLP benchmarks, especially as model size increases:
- On well-rounded language tests like MMLU and AGIEval, Llama-2-70B scores 68.9% and 54.2% - far above MTP-7B, Falcon-7B, and even the 65B Llama 1 model.
- For QA datasets like Natural Questions and QuAC, the 70B Llama 2 likewise beats smaller models by wide margins. It reaches 85% on TriviaQA - topping powerful models like GPT-3.5.
- Llama 2 posts major gains on common sense tasks like Winogrande, where the 70B model hits 80.2% accuracy.
- For targeted skills like coding (HumanEval) and logic (BoolQ), Llama 2 again prevails. The 70B model nearly doubles 7B models' scores.
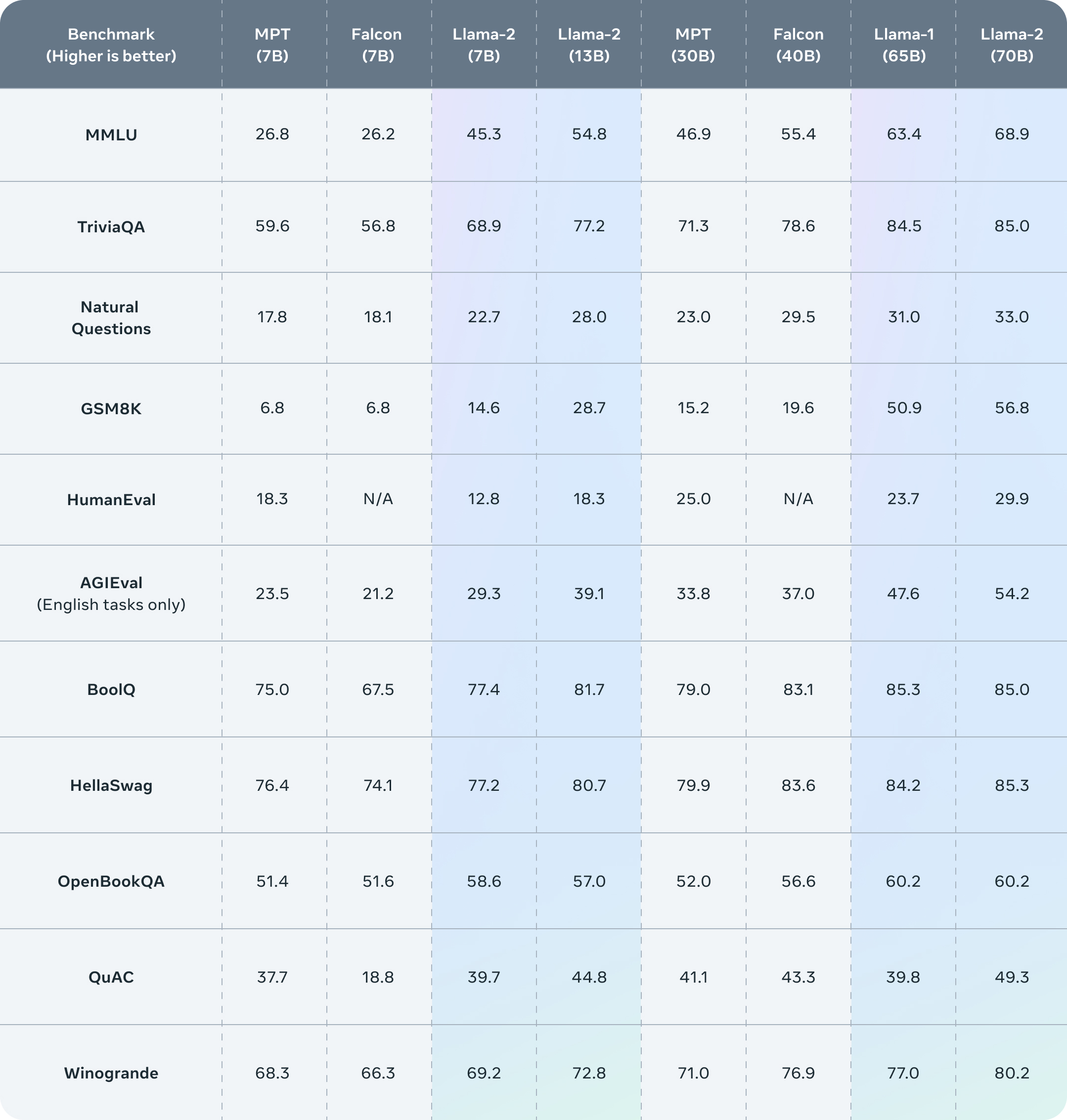
So across the board, Llama 2 sets new state-of-the-art results among publicly available LLMs. And performance reliably improves with model size, reaching up to 70B parameters. These benchmarks demonstrate Llama 2's well-rounded capabilities rivaling or exceeding proprietary models like GPT-3.5.
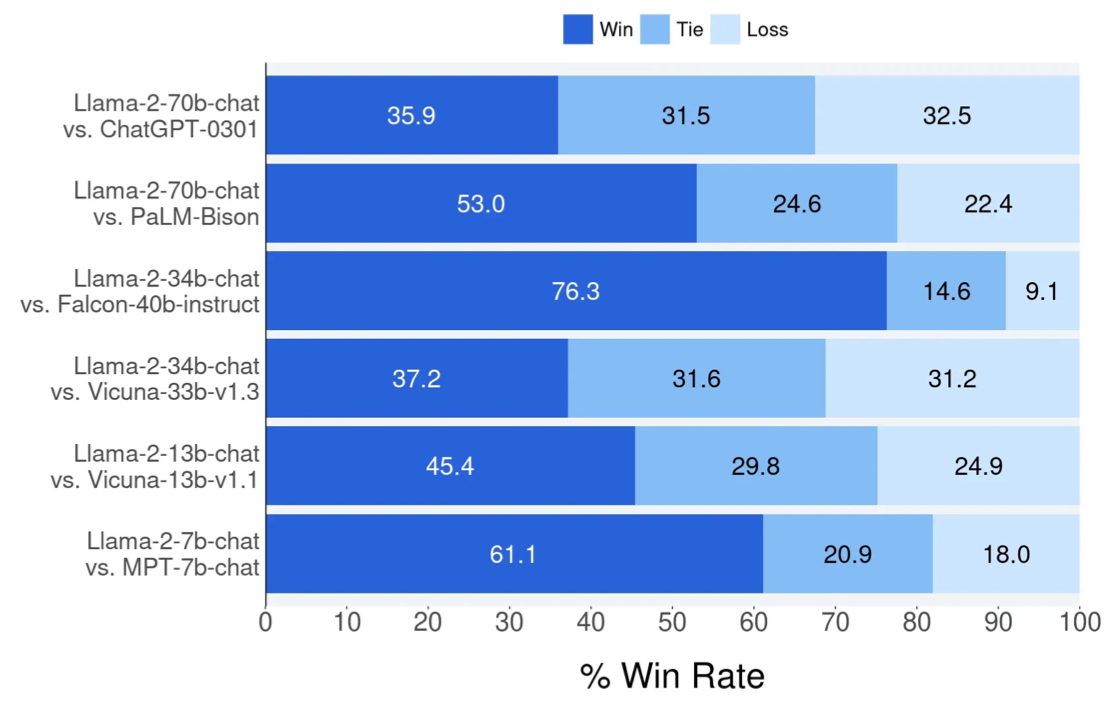
Llama 2 Shows Strong Helpfulness
Human evaluations of model helpfulness on ~4000 prompts show Llama 2-Chat competitive with or superior to other LLMs:
- Llama-2-70B beat ChatGPT-03 by over 4 points, with a 36% win rate. It also decively beat PaLM-Bison.
- Against other open source models, Llama-2-34B dominated Falcon-40B with a 76% win rate. The 13B Llama topped Vicuna-13B by 20 points.
- Even the smaller 7B Llama soundly defeated MTP-7B with a 61% win rate, over 20 points higher.
So across model sizes, Llama 2-Chat wins a plurality or majority of matchups with proprietary chatbots, demonstrating excellent helpfulness.
These human evals do have noise from subjective reviewing. But the consistent Llama 2 margins across multiple comparisons indicate a true helpfulness advantage - especially for larger model sizes.
With further tuning as an open source project, Llama 2-Chat's helpfulness could continue improving. For now, it appears on par with or better than closed competitors designed for assistive chat.
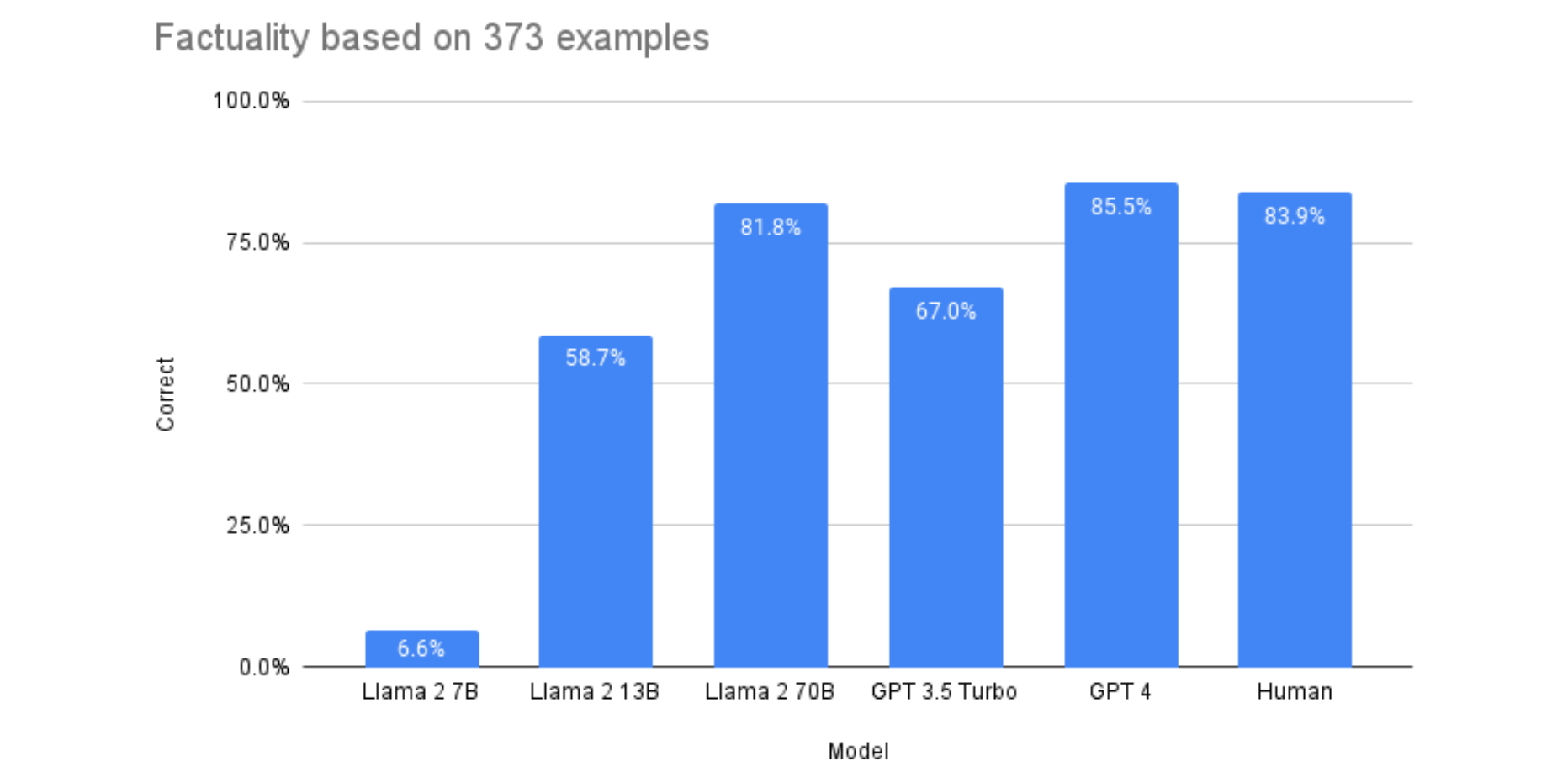
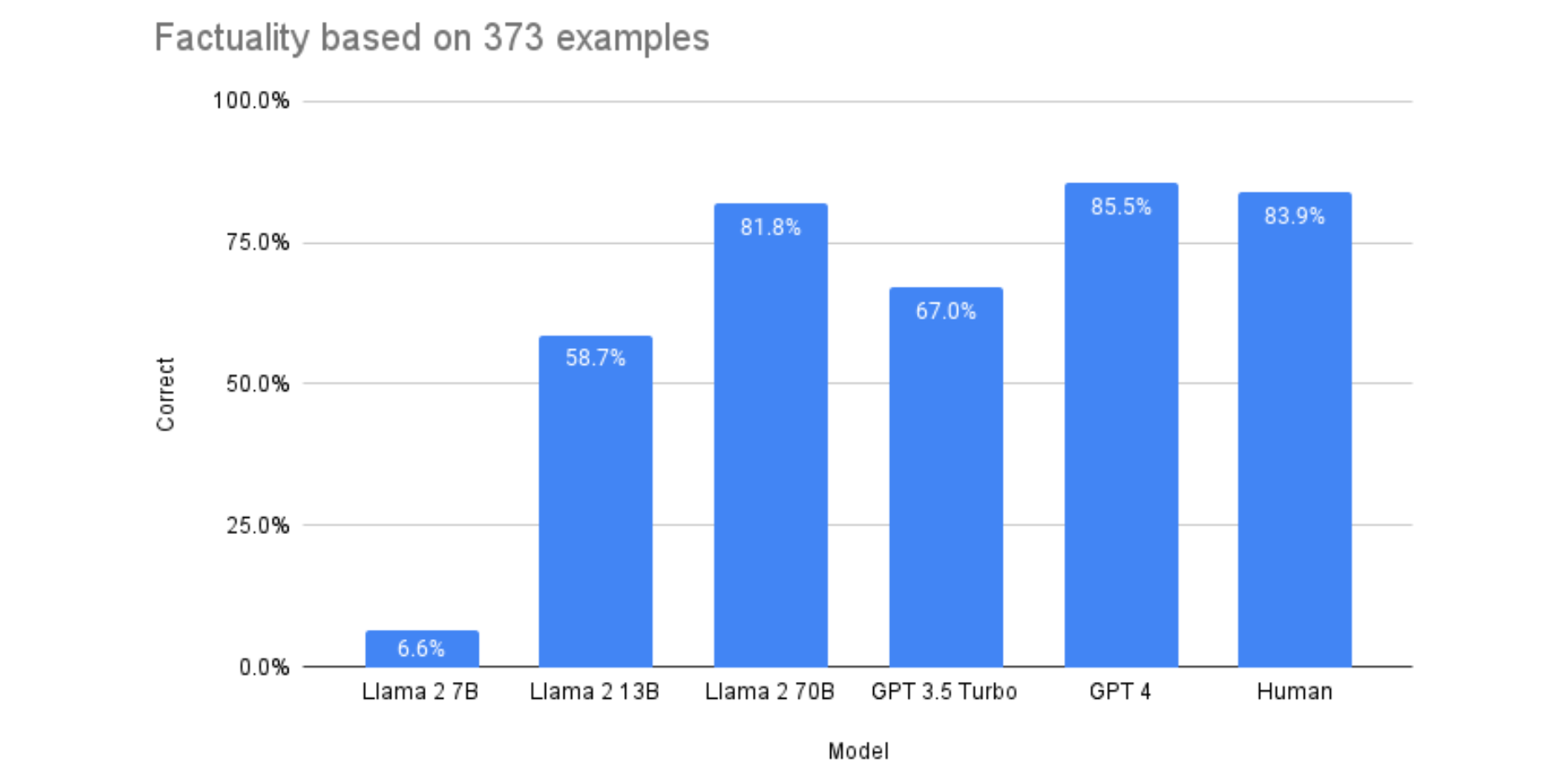
Llama 2 achieves near-human factual accuracy at low cost
In some experiments, we evaluated the factual accuracy of summaries generated by GPT-3, GPT-4, and different sizes of the open-source Llama 2 model. We tested their ability to identify factual inconsistencies in 373 news article summaries.
Surprisingly, we found the largest Llama 2 model (Llama-2-70b) matched GPT-4 in achieving 85% factual accuracy - on par with human performance. And it significantly outperformed GPT-3.5.
Yet Llama 2 costs just a fraction of closed models like GPT-4 and GPT-3. Even accounting for less efficient tokenization, Llama-2-70b was 30x cheaper than GPT-4. This makes Llama 2 viable for large-scale summarization applications requiring high factual integrity.
Llama 2 Competes on Accuracy Despite Lower Complexity
Llama 2 demonstrates impressive accuracy given its smaller size compared to GPT models:
- On the 5-shot MMLU benchmark, Llama 2 performs nearly on par with GPT-3.5, despite being smaller.
- In Meta's human evaluation of 4000 prompts, Llama-2-Chat 70B tied GPT-3.5 on helpfulness 36% of the time.
Llama 2 owes its strong accuracy to innovations like Ghost Attention, which improves dialog context tracking. This enables Llama 2 to stay competitive even at lower complexity.
However, GPT-4 significantly exceeds both Llama 2 and GPT-3.5 at MMLU as the largest and most advanced model. So for highly complex tasks, GPT-4 remains superior.
Llama 2 Matches GPT-4, Beats GPT-3.5
After accounting for potential biases, researchers found:
- Llama-2-70B scored 81.7% accuracy at spotting factual inconsistencies in summarized news snippets. This matches GPT-4's 85.5% accuracy.
- Both Llama-2-70B and GPT-4 significantly outperformed GPT-3.5-turbo, which scored just 67% due to severe ordering bias issues.
- Llama-2-70B and GPT-4 achieved near human-level performance of 84% accuracy on this fact checking task.
So Llama 2 demonstrates factual accuracy on par with GPT-4 and superior to GPT-3.5 when summarizing text. This validates the potential of Llama 2 for high-integrity summarization applications.
Llama 2 Demonstrates Advances Beyond GPT-3
While OpenAI's GPT-3 pioneered large language models, Meta's Llama 2 represents the next evolution in LLMs:
- Llama 2 was trained on 40% more data than its predecessor Llama, allowing it to learn from a broader range of public sources. This gives Llama 2 an edge over GPT-3.
- Llama 2 doubles the context length used during training compared to Llama 1. This enables stronger long-term reasoning versus GPT-3.
- On benchmarks like Codex HumanEval that assess coding skills, Llama 2 significantly outperforms GPT-3, demonstrating superior programming ability.
- Llama 2 also shows improvements on common sense reasoning tasks where GPT-3 remains limited, such as the Winogrande challenge requiring contextual cues.
- While GPT-3 struggles with factual consistency, experts believe Llama 2 is less prone to hallucinating facts during text generation.
So while GPT-3 pioneered large language models, Llama 2 proves they continue to rapidly advance. With architectural enhancements and abundant training data, Llama 2 pushes the boundaries of what's possible with general-purpose LLMs beyond GPT-3.
Llama 2 Stacks Up Impressively Against GPT-4
Though OpenAI's GPT-4 is considered the leading proprietary LLM, Meta's open-source Llama 2 reaches impressive performance on key benchmarks:
- Experts believe Llama 2 poses a real competitive threat to GPT-4 on language tasks, despite being openly available.
- In certain head-to-head evaluations by human raters, Llama 2 was judged to outperform GPT-4 on some prompts.
- Llama 2 approached GPT-4's high scores of 80-100% on exams like the LSAT and SAT, scoring 71.2% on the code-focused Codex HumanEval test.
- While GPT-4 improved substantially in areas like biology exams, Llama 2 made parallel strides in general knowledge by utilizing 40% more training data.
- For image classification on ImageNet, Llama 2 matched GPT-4's state-of-the-art 89.6% top-1 accuracy.
So while GPT-4 maintains strengths in some specialized domains, Llama 2 proves highly capable across a wide range of language and reasoning benchmarks, even exceeding GPT-4 in select contexts. As an open-source project, Llama 2 has ample room to continue advancing beyond current proprietary LLMs.
Smaller Llamas Struggled with Bias
However, smaller 7B and 13B Llama 2 models failed to follow instructions and exhibited extreme ordering bias. Their fact-checking accuracy remained far below random chance.
Bigger models like GPT-4 and Llama-2-70B were much better at avoiding these biases. So smaller Llamas may not be suitable for summarization tasks requiring rigorous factual diligence.
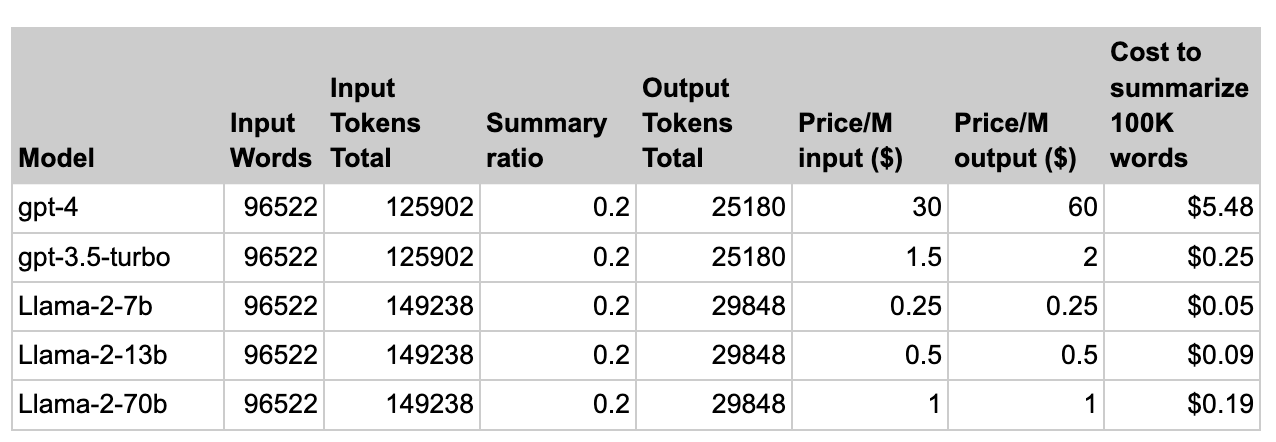
Llama 2 Offers Big Cost Savings Compared To GPT-3.5 and GPT-4
Importantly, Llama 2 is substantially cheaper than GPT models:
- Llama 2's cost per paragraph summary is ~30x less than GPT-4 while maintaining equivalent accuracy.
- Even accounting for less optimized tokenization, Llama-2-70B costs only about 10% more than GPT-3.5 to summarize at much higher factual fidelity.
So for organizations requiring high-quality summarization at scale, Llama 2 enables similar performance to GPT-4 for a fraction of the cost. Its open-source nature also allows ongoing improvements over time.
Best Use Cases for Each Model
While GPT-4 is more capable in some areas, Llama-2 maintains distinct advantages as an open-source alternative:
Llama-2 Strengths
- As a much smaller model, Llama-2 is the fastest and most efficient of the two, enabling cost-effective deployments.
- Llama-2 costs approximately 30 times less per usage than GPT-4, making it accessible for organizations with tighter budgets.
- Being open source allows Llama-2 to be modified and self-hosted, ensuring better data privacy and security compared to closed models.
- For summarization, Llama-2 matches GPT-4's factual accuracy according to experiments, making it suitable for high-integrity NLP.
Llama-2 Weaknesses
- In benchmarks of mathematical reasoning, GPT-4 significantly outperforms Llama-2, with superior analytical abilities.
- GPT-4 achieves a higher overall evaluation score across NLP datasets due to its larger scale.
- With expanded context lengths and multilingual support, GPT-4 remains better suited for longer, more complex textual inputs.
A Note About Data Security & Privacy
Llama-2's open source nature makes it a good fit for use cases where privacy and security are critical concerns:
- For companies or individuals wanting a zero trust environment, Llama-2 allows sensitive parts of an AI workflow to be contained completely internally with no external data exposure.
- Since Llama-2 can be self-hosted and modified, it provides more control over data and models for privacy-focused use cases.
Comparatively, companies that do not have stringent data privacy needs and are comfortable trusting an SLA with OpenAI may opt for GPT-4 or GPT-3.5 for other use cases:
- Small business chatbots can utilize Llama-2's conversational skills at low cost.
- Enterprise chatbots can leverage GPT-3.5's reasoning for complex customer service.
- Mission-critical chatbots can tap into GPT-4's analytical capabilities.
So in situations where privacy is a major factor, Llama-2's open source nature offers inherent security advantages over closed models. But for other use cases not sensitive to data exposure, GPT-4 and GPT-3.5 remain strong options.
Best Use-Case for Llama-2
Llama-2's open-source nature, efficiency, and low cost make it a great choice for more budget-conscious use cases that don't require top-tier reasoning abilities:
- Small business chatbots benefit from Llama-2's conversational skills at a fraction of the cost of commercial alternatives. The model can handle common customer service needs.
- Non-strategic social media content generation leverages Llama-2's language fluency without demanding high levels of creative sophistication.
- Research and academic applications can tap into Llama-2's capabilities while tailoring the model as needed thanks to its open source license.
For moderately complex enterprise use cases, GPT-3.5 strikes a balance between performance and affordability:
- Enterprise chatbots for customer service can take advantage of GPT-3.5's robust reasoning for handling more complex conversations.
- Content creation support optimizes marketing workflows by allowing GPT-3.5 to rapidly generate drafts and creative jumping-off points for human copywriters.
Finally, for the most advanced use cases requiring top-tier reasoning, creativity, and availability at scale, GPT-4 remains the premier option:
- Mission-critical chatbots that tackle the most nuanced customer issues lean on GPT-4's exceptional analytical abilities.
- Automated content creation harnesses GPT-4's creative prowess to produce high-quality copy with minimal human oversight needed.
So for businesses requiring top-tier reasoning at scale, GPT-4 still leads. But Llama-2's open-source nature, low cost, and customizability make it an appealing alternative for a wide range of use cases.
Summary & Takeaway
Llama 2 Competes on Accuracy Despite Lower Complexity
Llama 2 demonstrates impressive accuracy given its smaller size compared to GPT models:
- On the 5-shot MMLU benchmark, Llama 2 performs nearly on par with GPT-3.5, despite being smaller.
- In Meta's human evaluation of 4000 prompts, Llama-2-Chat 70B tied GPT-3.5 on helpfulness 36% of the time.
Llama 2 owes its strong accuracy to innovations like Ghost Attention, which improves dialogue context tracking. This enables Llama 2 to stay competitive even at lower complexity.
However, GPT-4 significantly exceeds both Llama 2 and GPT-3.5 at MMLU as the largest and most advanced model. So for highly complex tasks, GPT-4 remains superior.
GPT-4 Leads in Creativity
GPT-4 also demonstrates greater creative ability according to benchmarks:
- When generating poetry, GPT-4 produces the most advanced vocabulary and expressions, reflecting its higher complexity.
- For coding benchmarks like HumanEval, GPT-4 more than doubles Llama 2's accuracy at 67% vs. 29.9%.
So while Llama 2 competes on overall accuracy, GPT-4's immense scale enables greater creative potential. For tasks requiring human-like originality, GPT-4 is still the most capable option between the models.
An Open Source Contender
As an open-source project, Llama 2 has the potential to rapidly improve with community development. And its competitive initial benchmarks validate it as a leading open LLM option.
For organizations seeking an alternative to costly proprietary chatbots, Llama 2 represents a free high-quality model with untapped potential. Its code and training data are fully available to tweak and expand.
Of course, LLMs require careful use to address risks like bias and misinformation. But Meta's transparency about Llama 2 enables responsible open development - key to realizing the promise of AI while maintaining oversight.
As Meta continues expanding the model and community, Llama 2 could soon become the go-to open-source foundation for state-of-the-art natural language applications.

Comments